Some Lagniappe for You
by Tiny Ruisch
la·gniappe (lnyp, ln-yp)
n. Chiefly Southern Louisiana & Mississippi
1. A small gift presented by a store owner to a customer with the customer’s purchase.
2. An extra or unexpected gift or benefit. Also called regionally boot.
For the past couple of months, I’ve been working on my latest club project in my spare time. I hope to get all of the club newsletters scanned and posted on the web site. It is a time consuming job, but I think it is an important part of the clubs history.
I could just scan each page, combine into a PDF file and post to the website. The problem with using that simple, easiest method is that the files would not be indexed by the Google web site search engine. I spent so much time setting up the web site custom search that this became an untenable alternative. I needed some good optical character recognition software (OCR).
I’m a scanning rookie. By that I mean I have never used a scanner for anything but scanning old pictures and the occasional document. This whole project has been a learning experience for me. I hope everyone thinks the results are satisfactory.
The first thing I learned is that many of the OCR scanning programs use the same engine, Tessaract OCR. Tesseract is a commercial quality OCR engine that was originally developed by HP. It was open sourced in 2005. Click this link for An Overview of the Tesseract OCR Engine. There are many OCR software packages (both free and paid) using Tesseract. All of them are just “wrapper” interfaces.
After a thorough search of reviews, a few test downloads and several second thoughts, I did what I often do: go with Gizmo’s recommendation. I downloaded and installed FreeOCR. FreeOCR is a free Optical Character Recognition Software for Windows. It supports scanning from most Twain scanners and can also open most scanned PDF files and multi page Tiff images as well as popular image file formats. The interface is intuitive and the program is easy to use.
FreeOCR processes only one image at a time, but it will OCR multi-page PDF files. There is no limit on file size. FreeOCR can create Word and RTF documents from the text it extracts, but it’s just pasted text. There is no attempt to reconstruct the document or place images. Most importantly, text scanning conversion is excellent.
There is an Online Help Menu, but you will likely only have to look at it once or twice. To use the program, simply open a document by scanning, opening a file or opening a PDF. You can either select the entire page or draw a box around part of the image. Then press the OCR button to process your selection. The original image is on the left panel and the OCR text is on the right.
The left panel has nine menu items (the small icons on the left of the pane). From top to bottom, you can select next page, previous page, fit image to screen, fit width to screen, enlarge, reduce and rotate either counter or clockwise. The bottom icon (the little square) is the most used and the most useful. Clicking it opens the selection menu allowing you to crop the image to your selected area or copy the entire image to the clipboard.
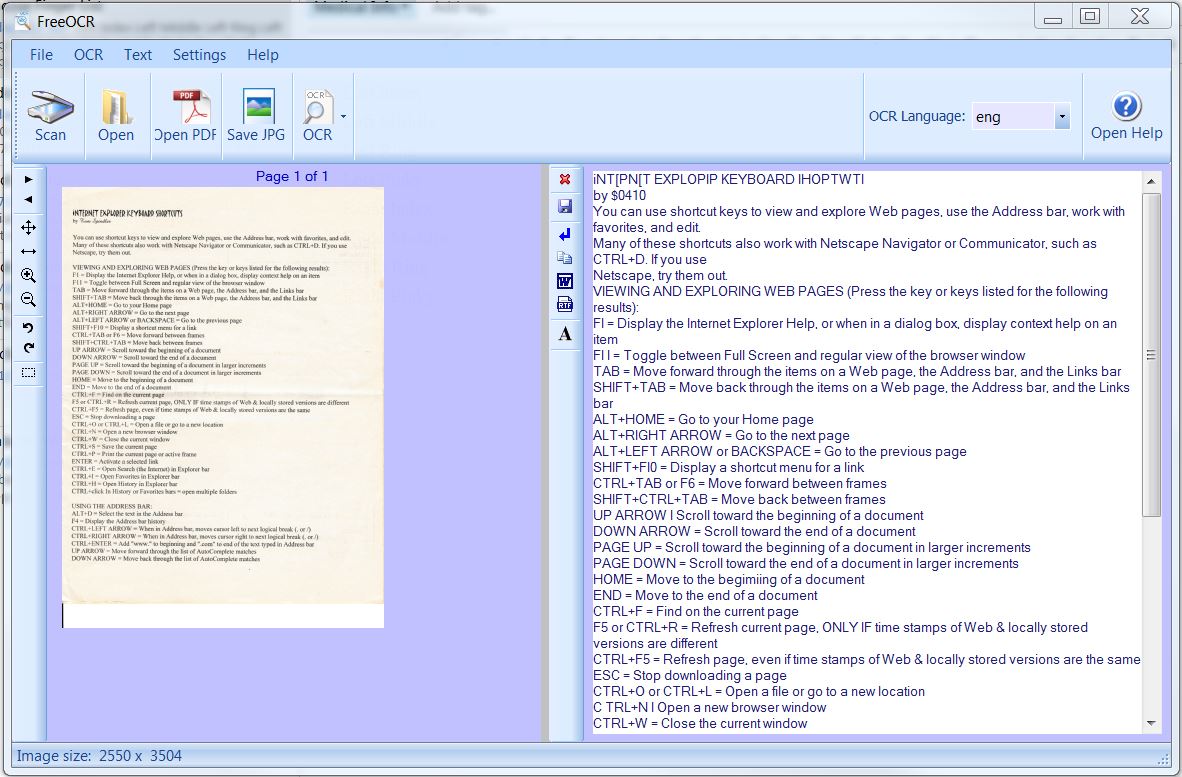
Similarly, there are seven menu items in the text panel on the right side. From top to bottom, you can clear the text window, save text, remove line breaks, copy all the text to the clipboard, export text into Microsoft Word, export text as RTF or change the font size. In my setup, I copy the text to the clipboard and then paste into Scibus. Most of the text editing required is deleting extra spaces, changing the number 1 to a lower case letter l or changing the capitalization of the x. The program doesn’t reliably convert some fonts. After about fifty edits it got much easier as I learned what errors to look for. When I am done editing the text, I select images and copy them to the clipboard. Then I paste them into the document. I don’t spend a lot of time making them perfect because I think the important part of the newsletters is the articles and being able to search them on the club website.
FreeOCR is freeware OCR & scanning software and you can do what you like with it including commercial use. The included Tesseract OCR engine is distributed under the Apache V2.0 license. I recommend downloading the program from the home page.
If you like the program, just tell everyone that you’ve got a SWLAPCUG extra, a bonus perk, a small gift, a present from the club: a little lagniappe.